我正在尝试从该网站收集所有图像文件名:https://www.shipspotting.com/
我已经收集了一个包含所有类别名称及其 ID 号的 Python 字典
cat_dict我已将 https://www.shipspotting.com/ssapi/gallery-search 确定为加载下一页内容的请求 URL。但是,当我使用 requests 库请求此 URL 时,我收到 404。我需要做什么才能在加载下一页内容时获得正确的响应?
import requests
from bs4 import BeautifulSoup
cat_page = 'https://www.shipspotting.com/photos/gallery?category='
for cat in cat_dict:
cat_link = cat_page + str(cat_dict[cat])
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:96.0) Gecko/20100101 Firefox/96.0",
"Referer": cat_link
}
response = requests.get('https://www.shipspotting.com/ssapi/gallery-search', headers=headers)
soup = BeautifulSoup(response.text, 'html.parser')
https://www.shipspotting.com/photos/gallery?category=169 是示例页面 (
cat_link每次向下滚动页面时,都会向服务器发出一个新请求(带有特定负载的 POST 请求)。您可以在开发工具的“网络”选项卡中验证这一点。
以下作品:
导入请求
从 bs4 导入 BeautifulSoup
###根据页面数量将以下代码放入for循环中
### [船舶照片总数]/[12],或异步...您的选择
数据= {“类别”:“”,“每页”:12,“页数”:2}
r = requests.post('https://www.shipspotting.com/ssapi/gallery-search', data = data)
打印(r.json())
这将返回一个 json 响应:
{'page': 1, 'items': [{'lid': 3444123, 'cid': 172, 'title': 'ELLBING II', 'imo_no': '0000000',....}
您识别的网址包含通过 API 作为 post 方法的数据,无限滚动使下一页意味着从 api 的有效负载数据进行分页。
工作代码以及响应 200
import requests
api_url= 'https://www.shipspotting.com/ssapi/gallery-search'
headers={'content-type': 'application/json'}
payload= {"category":"","perPage":12,"page":1}
for payload['page'] in range(1,7):
res=requests.post(api_url,headers=headers,json=payload)
for item in res.json()['items']:
title=item['title']
print(title)
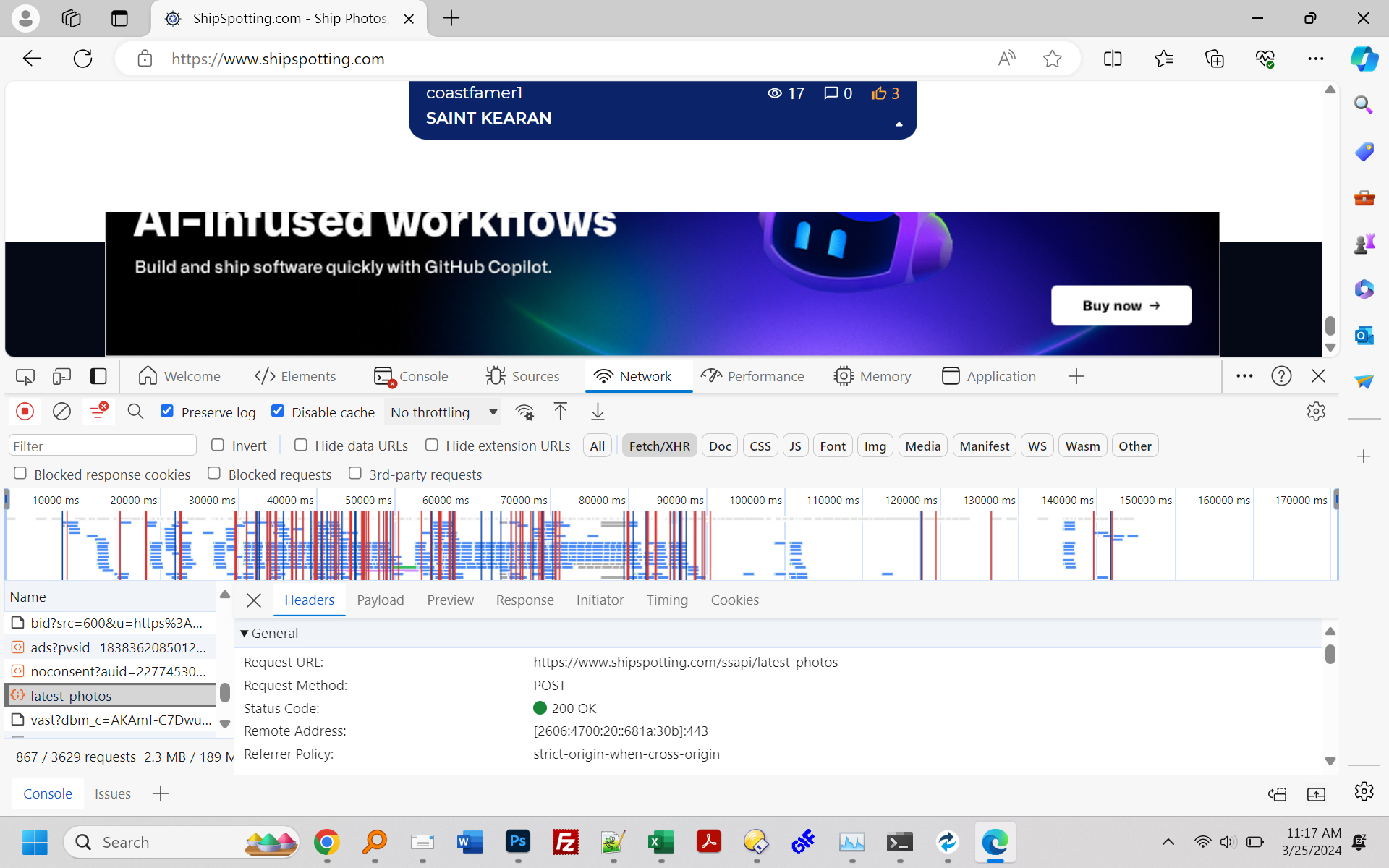
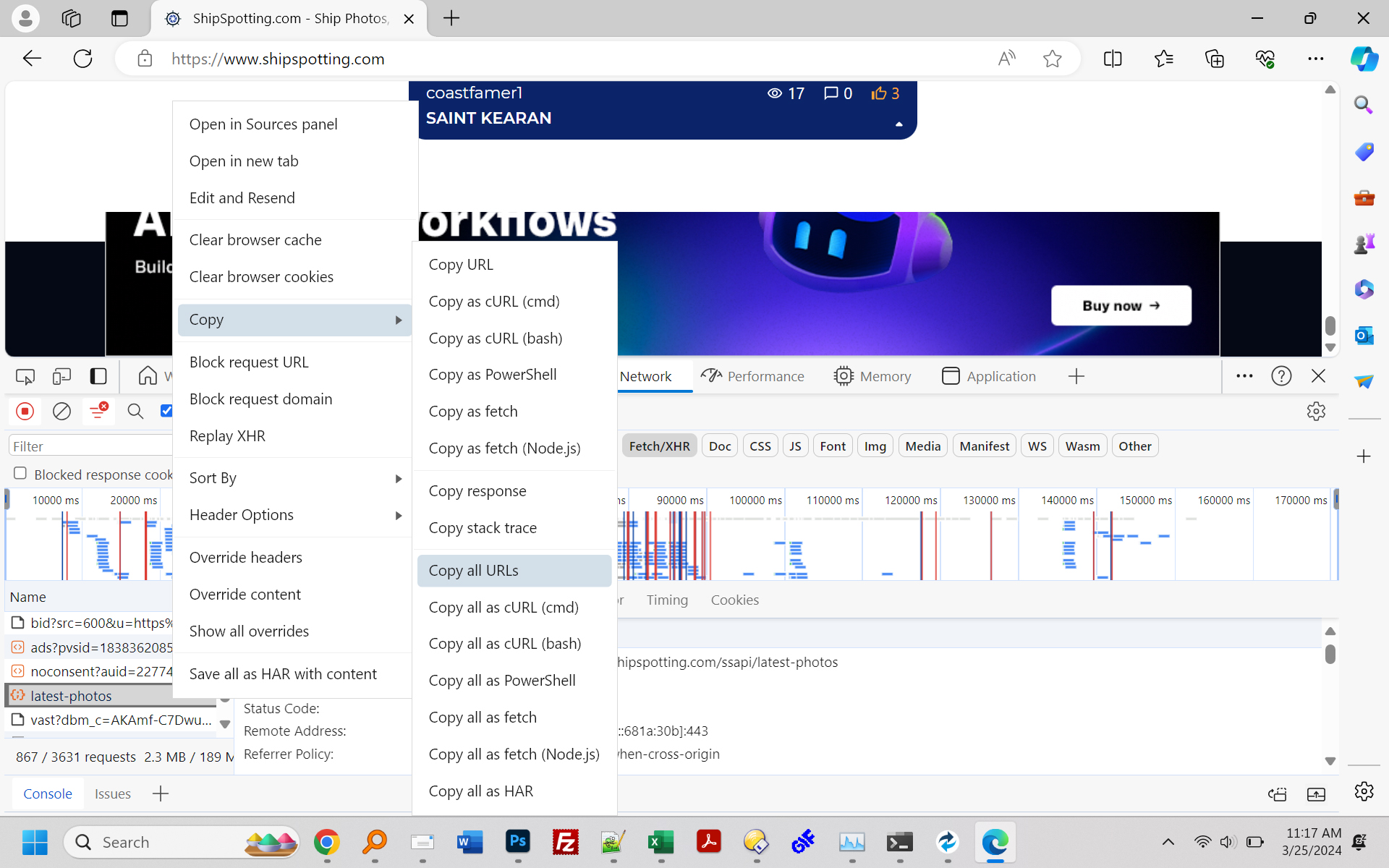
如果您需要的只是图像文件名,也许还有图像,这就是我所做的,在另一个网站上为我工作。我访问了您的船舶网站,并在 Edge 中打开了 Inspector(许多其他浏览器将具有相同的工具)。我选择查看“网络”请求,并将过滤器设置为查看“Fetch/XHR”。然后我刷新了页面,并开始向下滚动。当您到达页面底部时,将会发生“最新照片”网络请求。我不断点击“结束”以到达新加载项目的末尾,并允许网站加载更多项目。当我厌倦了点击“结束”按钮后,我单击了网络列表中的最后一个“最新照片”条目,右键单击,然后选择“复制所有 URL”。我将它们粘贴到文本编辑器中,发现大约 800 个指向不同大照片的链接,所有格式如下: https://www.shipspotting.com/photos/middle/9/9/2/3691299.jpg?cb=0 我一直在尝试使用 perl 从无限加载的网页中抓取照片,但无法使其工作,并提出了这个解决方案,至少对于您感兴趣的网站来说是这样。 这是我的工作的两个屏幕截图: [1]:http://app25.com/shipspotting_1.jpg [2]:http://app25.com/shipspotting_2.jpg
{kind=link}
{kind=link}
{kind=link}